The Digital History Fellowship has enabled the Digital History Fellows to work across the many projects at the Roy Rosenzweig Center for History and New Media. Through these experiences I have had the opportunity to work with a number of tools, develop familiarity with various languages, and learn more about project development.
Digital Campus
Among the responsibilities of digital history fellows is the production of the Digital Campus podcast. Fellows are responsible for scheduling the recording, finding stories for the hosts, recording the conversation, processing the audio files, and writing a blog post that describes the podcast. Below are the podcasts that I have contributed to:
RRCHNM20 Site
Using Omeka the 2013-2015 cohort of digital fellows worked in Spring 2014 to develop and build a digital archive of the 20 year history of RRCHNM. Beginning in a seminar with Dr. Robertson, we established a framework for the site, collected data on one of the Center’s projects, and created items within an Omeka installation. Over the course of the summer I continued these activities, learning a great deal about the grant-writing process and the complexities of working on large scale digital projects. Visit the link to see the product of these efforts.
20th Visualization
At the RRCHNM Anniversary conference I worked with a group of others to mine the RRCHNM20 website to create a d3 visualization of the center’s history. In this series of network visualizations, it is possible to uncover the hidden connections between individuals and projects at RRCHNM.
Blog Posts
Below is a collection of the blog posts I have composed in my time as a Digital Fellow at CHNM. In many cases I am reflecting on the time I’ve spent on a particular project or I discuss the activities undertaken within a single division.
Reflections on the Fall Semester
It has been a busy and beneficial fall semester as a second-year fellow at CHNM. The time rolled along quickly and throughout I’ve had a number of new opportunities and experiences that have built on the work that we did last year as first-year fellows.
As a second-year fellow in the center, our roles at the center changed considerably. The first year of the fellowship focused on circulating us through each division at the center - a six-week process that exposed us to the various projects and enabled us to work with faculty and staff throughout CHNM. The second year of the fellowship has been much more concentrated. My work in the Education division has afforded me more time on a project and allowed me to work more directly with members of that division. In turn I’ve been able to understand the facets of the project to which I have contributed and have enjoyed greater integration into the division.
Getting Started with Phase 1 of 100 Leaders:
In this case, the majority of the fall semester was spent working on the 100 Leaders in World History project. The site, which I have reviewed here, allows for interaction with historical figures on the subject of leadership and encourages teachers and students to extend these subjects further by rating these figures on particular leadership traits. CHNM was selected by National History Day to develop and design the site last Spring. At the start of the semester the site was still in the first phase of development. I worked to add the content from National History Day to each of the pages and familiarized myself with the back-end structure of Drupal. Throughout this period I had a number of interesting conversations with Jennifer Rosenfeld about the complexities and challenges of creating interactive and educational materials for the web. I learned a good deal about the importance of collaboration on a project of this scale. With over 100 distinct pages on the site, minor edits, like the addition of italicization, called for discussion, notation, and a division of labor to ensure that each page was updated appropriately.
Mentoring and moving into Phase 2:
As the semester rolled on, the first-year fellows circulated into the Education department for a four-week accelerated rotation. Stephanie, Jordan, and Alyssa each completed a blog post that described their experiences. During this period I took on a larger role in mentoring them and organized each of the activities we would undertake. We began with user testing across browsers and devices. At this stage, the 100 Leaders in World History project had entered the second phase of development and this user testing aided in the development and design of the current voting interface and served to test and validate that the underlying voting algorithm was capturing and recording appropriately. We consistently tried our best to break everything and shared our findings with Jennifer and James McCartney for improvement. (Anyone viewing the site on a smartphone will appreciate our feedback as the larger slider buttons were a direct result of these tests!)
Next, we worked to gather image content and citation information for videos on the site. At first, our discussions focused on digital images and copyright, but soon we turned our attention to issues of diversity and representation in terms of time period, geographic region, gender, race, ethnicity, and type of leadership. We tried to be thoughtful in our selections, considering the ability of a single image to convey particular types of information about a leader or juxtaposing images to create alternate or additional meaning about a figure or figures. The final activity undertaken with the help of the first year fellows was the creation of a guidebook that will aid National History Day in modifying and maintaining the 100 Leaders in World History site.
Each of these activities was useful in demonstrating the different complications that accompany large-scale, collaborative, educational websites. User testing encouraged us to deal with the user experience and to gain insight into the processes required to build a site of this size. Contributing images moved us back into our comfort zones as historians doing research on particular subjects- but the added complication of copyright was useful in expanding the Fellows’ thinking about what digital historical research entails. While we each campaigned for our favorite images or leaders, we also took seriously the importance of crafting a meaningful visual narrative that supported the dialogue of each video. Finally, the guidebook allowed an introduction to the back-end of a Drupal site and encouraged us to think through questions about making navigation easier and more efficient to those without experience programming.
Working on 100 Leaders after the launch:
After the first-year fellows completed their rotation in the Education division, my work continued to focus on the completion of the Guidebook as well as video transcription, user testing, data manipulation and a website review. On November 3rd, the voting interface on the 100 Leaders in World History site went live. To aid in marketing the site and to inform teachers about how it could be used in the classroom, I wrote a summary of the site’s features for Teachinghistory.org. This website review encouraged me to revisit my earlier discussions with Jennifer about online learning and to view the 100 Leaders in World History site with fresh eyes. Since then, interest in the site has exploded and we have recorded over 200,000 votes in just over a month. It has been a busy but useful semester for me in Education and I’m glad to have had the opportunity to contribute to a project like 100 Leaders.
CHNM Anniversary:
In November, CHNM celebrated its 20th anniversary with a conference held here at George Mason. As I described here, the second-year fellows spent a portion of last spring engaged in a discussion about the history of the center. From that seminar with Dr. Robertson, each of us researched a foundational project in the center’s history and created an archive in Omeka to organize and display our findings. Over the summer I worked to expand our efforts to include the broader range of projects using grant materials, oral histories, and internal communications to trace the development and growth of important projects. As a relative newcomer to the field, this process was particularly meaningful. This work culminated this fall in the release of the RRCHNM20 Collection which made these materials public and invited others to contribute. The RRCHNM20 Collection is an important step toward creating a unified narrative of CHNM’s role through recording and preserving the hidden processes and persons at each phase of CHNM’s history. In fact, a group of us used a portion of our time at the conference to mine the RRCHNM collection and create a visualization that represents some of the connections between projects and people across 20 years. Furthermore, the conference events brought former and current employees together in a productive and meaningful dialogue about the past, present and future of work at DH centers like CHNM (I live-tweeted these experiences throughout the conference.)
Additional Fellowship Responsibilities and final thoughts:
The additional responsibilities of a second-year fellow include producing a podcast, serving as a mentor to first-year fellows and the operation of the Digital Support Space. It was interesting to be on the other side of the mentorship process this year. Last year, Ben Hurwitz, Spencer Roberts, and Amanda Morton served as mentors to the incoming fellows. They were each very helpful to us and I was excited to provide the same assistance for the new group. Across the semester I’ve made myself available to each of them for support, but my interaction during their rotation in the Education division was particularly significant. During that period I was able to provide direct support and work with each of them individually on a project. Not only do I feel that I got to know them better, but we had a number of useful conversations about the fellowship and the PhD program broadly. I also worked this semester with my mentee, Jordan, to research and produce episode 108 for the Digital Campus podcast. Finally, I also extended time and resources to individuals in Clio I, Clio 3, and Digital Storytelling classes through the Support Space.
Overall, has been a fast and busy semester but a successful one. I’ve learned a good deal about project management and collaboration through my experiences on the 100 Leaders in World History project and I’m pleased to have had the chance to work more closely in the Education division.
First-Year Review
Our spring semester as Fellows at the Center passed remarkably quickly (not solely a result of the frequent snow days but cancellations definitely contributed to the rapid approach of summer). We were kept very busy with projects for the Research division and an intensive DH Seminar this semester. Below I’ll briefly describe some of the activities we undertook throughout this period and reflect on my first year fellowship at CHNM.
The semester started with six weeks in the Research division - by far the most intimidating to someone that is new to DH. Quickly, however, we were put to work on several engaging projects and I found that I acclimated without feeling overwhelmed. We learned about PressForward by doing some user testing and improving the documentation for the plugin. We also were able to learn about the grant-writing process by doing some research for an upcoming project and we got a clearer idea of how plugins and tools are developed at the center. The majority of our time in this division was spent on the challenging task of using digital tools to uncover information about THATCamp. We blogged about the process of being set loose on the contents of THATCamp and the scraping and topic modeling we performed (those posts are available here). We shared these results in a center-wide presentation and received a lot of support and feedback for the project.
Across the semester the Fellows also focused time on providing support and assistance to other students. As many of us were also enrolled in Clio 2, we were visited many of our classmates and our table was often filled with students collaborating on skills and resources. With assignments that required significant use of digital tools, we handled questions regarding Photoshop and Dreamweaver, sought new resources and tools, and helped find errors in HTML or CSS. I saw a huge benefit in working through problems and took a lot of inspiration from the advice and suggestions of everyone at the table.
Finally, our semester came to a close as we spent the last six weeks in a seminar with Dr. Stephen Robertson. The seminar built on the experiences within each department at the Center and, with this base of knowledge, asked us to turn our gaze outward at the digital humanities as a field and DH centers as centers of production. This discussion was also a timely one, as this fall CHNM will celebrate its 20th anniversary and the Center has begun to reflect on this period. We used Diane Zorich’s work on DH centers with readings by Mark Sample, Stephen Ramsay, Bethany Nowviskie, Neil Fraistat, Elijah Meeks and Trevor Owens, to frame our discussions and answer questions about where, when and how DH work has been done.
Using centerNet as a starting place, we tried to unpack a larger history of digital humanities labs and centers. This process raised interesting questions for us about the differences between a resource center, library service desk, institutional organization and brick-and-mortar DH center. Projects, staff, infrastructure, institutional support and audience were among the issues we considered, but we were also curious about how these locations are linked through shared resources, staff and projects.
Next we dug into the history of CHNM. Oral histories have been collected from participants at the center- but we soon realized that the overview these interviews provided would be only part of the picture of CHNM. In order to further unpack this history, we would need to dive into the projects themselves. Each of us examined a pivotal project. For me this was ECHO, a web portal for the history of science and technology. Working through grant materials enabled me to make connections between this early project and current/recent projects like Hurricane Digital Memory Bank, Zotero, and Omeka. Using ECHO as a vantage point, I gained greater insight into the transitions the Center has seen - from an emphasis on CD-ROMs and single-subject websites to building tools that enable us to organize, analyze, present, and use content in new ways. Understanding and unpacking this trajectory was very useful for me and a meaningful part of my semester.
Looking across my year at CHNM, I’m very happy with the time we spent in each division. Walking into the center can be an intimidating process. One has the immediate sense that you are entering a place where things happen, where goals are made, met, and exceeded. It was very hard to imagine my place in the midst of such an accomplished group of people. With a limited digital background - this was a year of learning, asking questions and digging up online tutorials. The Center has been a remarkable resource toward that goal. Cycling through each division exposed us to a variety of projects and workflows and I’ve learned a great deal through this process. Though each division responds to their own set of concerns and audiences, there is a definite cohesion to the work that is done. It has been remarkably informative to have played a small part in that process.
THATCamp Mallet Results
(This post was created in the Spring of 2014 as part of a collective project undertaken by the 2013-2014 cohort of Digital History Fellows at RRCHNM. Each of the subsequent posts (written by individual fellows or collectively) originally appeared at the Digital History Fellowship Blog. These posts have been added to my blog to provide an comprehensive representation of the project. THATCamp Mallet Results was posted by Anne McDivitt.)
We have spent the last few weeks working to build a python script that would allow us to download and prep all of the THATCamp blog posts for topic modeling in MALLET (for those catching up, we detailed this process in a series of previous posts). As our last post detailed, we encountered a few more complications than expected due to foreign languages in the corpus of the text. After some discussion, we worked through these issues and were able to add stoplists to the script for German, French, and Spanish. Although this didn’t solve all of our issues and some terms do still show up (we didn’t realize there was Dutch too), it led to some interesting discussion about the methodology behind topic modeling. Finally we were able to rerun the python script with the new stopwords and then feed this new data into MALLET.

MALLET, or MAchine Learning for Language Toolkit, is an open source java package that can be used for natural language processing. We used the Programming Historian’s tutorial on MALLET. Topic modeling is an important digital tool that analyzes a corpus of text and seeks to extract ‘topics’ or sets of words that are statistically relevant to each other. The result is a particular number of word sets also known as “topics.” In our case we asked MALLET to return twenty topics based on our set of THATCamp blog posts. The topics returned by MALLET were:
- xa digital art history research university scholarship graduate field center publishing open today institute cultural knowledge professor online world
- university games pm humanities http digital september knowledge kansas saturday game conference state registration play information representation workshop boise
- thatcamp session sessions day participants free technology page unconference university nwe conference discussion information google propose hope event proposals
- people make time questions things idea access process ideas world work great making lot build add kind interesting nthe
- digital humanities data tools text projects research scholars omeka texts tool analysis scholarly archive reading online based book scholarship
- digital humanities session dh library libraries support projects open discussion librarians amp talk work journal sessions propose faculty list
- history public digital historical collections museum media project projects mobile online maps museums collection historians users sites site applications
- games zotero thinking place game code end cultural chnm hack year documentation humanists version number pretty application visualization set
- session open area data workshop tool knowledge teach interested bay prime bootcamp gis workshops reality night thatcampva virginia lab
- work interested students ways teaching post working talk writing blog love issues don conversation create collaborative thinking start discuss
- project web content information tools community resources archives experience research create learn creating learning share development materials specific provide
- xb xa del se humanidades digitales xad al madrid www mi este aires buenos digital personas taller cuba parte
- caption online id align width open attachment accessibility women read university american building accessible gender media november floor race
- data http org session www open twitter texas good wikipedia nhttp status wiki start commons drupal metadata people crowd
- xa workshop session omeka publishing http gt propose org workshops friday docs open hands amp doc studies topic discuss
- students digital learning technology education media college faculty humanities research game pedagogy student courses classroom assignments skills arts social
- xa oral digital humanities video event local application community offer interviews planning center education software jewish weekend college histories
- een het voor op te zijn deze met workshop kunnen om digitale bronnen data onderzoek historici nl wat worden
- social media technology studies arts performance museums xcf play participants cultural performing reading st email object platforms interaction technologies
- xa thatcamp org http thatcamps details read movement published planned access nthatcamp browse software follow break series google join
As you can see we have an impressive list of terms. Before we organize them in a meaningful way, we will briefly point out a common problem that scholars may confront when working with MALLET. As you may notice, we realized that we have quite a few errors such as ‘xa’ that appear in the results. While we don’t have a great answer for why this is, we think it has to do with complex encoding issues related to moving content from a Wordpress post that is stored in a MySQL database using Python. Each of these uses a different coding system and the error appears to be related to non-breaking spaces. A little bit of Googling revealed that the non-breaking space character used by Wordpress is ‘ ’ which is different that the ASCII encoding of a non-breaking space ‘/xa0’. When Python reads Wordpress’s non-breaking space character ‘ ’, it understands the space but encodes it as the UTF-8 version ‘/xa0’. As second year fellow Spencer Roberts explained the issue is that meaning is lost in translation. He used this analogy: Python reads and understands the French word for “dog” then translates it and returns the English word.
In this case, what shows up in our results is not ‘/xa0’ but rather ‘xa’ because we had stripped out all of the non-alphanumeric characters prior to running the data through MALLET. We think the errors such as ‘xa’ and ‘xb’ are because of these encoding issues. Anyone interested in clarifying or continuing this discussion with us can do so in the comments.
Returning to our MALLET results, our next challenge was to present and analyze the large amount of data. We drew from both Cameron Blevins and Robert K. Nelson in our approach and decided to group the topics by theme so that trends could be more easily identified. We determined that there were about seven broad themes in the corpus of THATCamp blog posts from 2008 to present:
- Accessibility
- Building
- Community
- International
- Pedagogy
- Public Digital Humanities
- THATCamp Structure
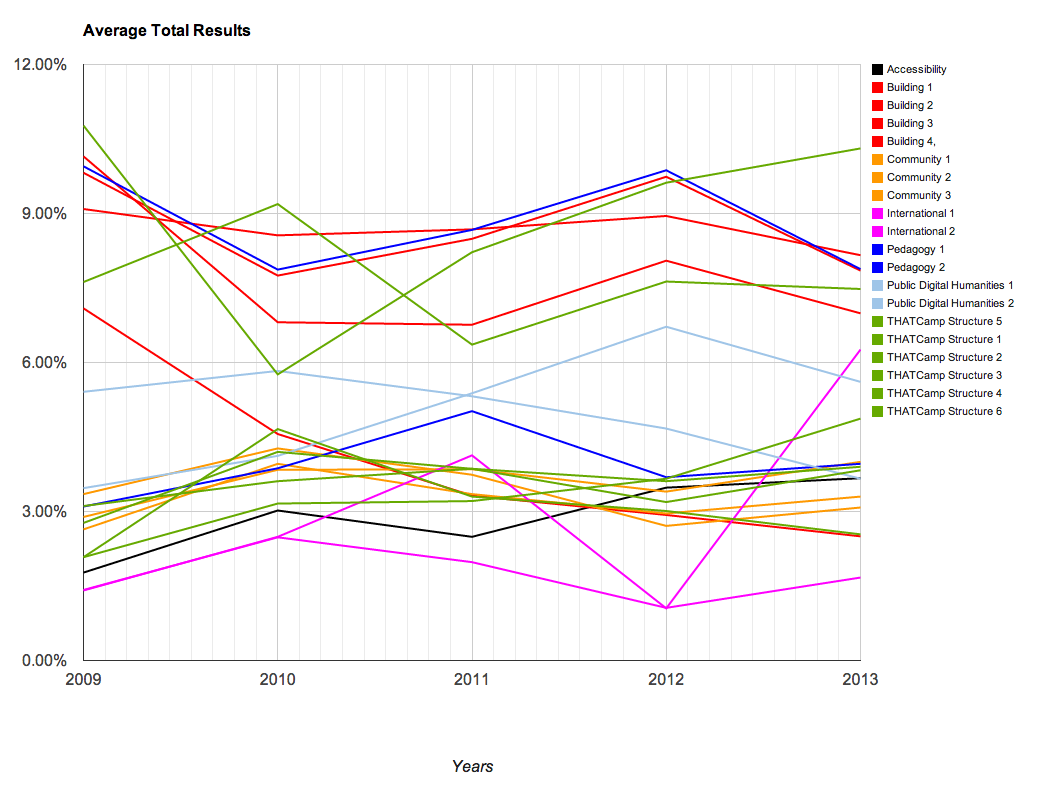
Utilizing these larger categories, we were able to create several charts that demonstrate the changes over time with the THATCamps. The charts are available below; you’ll note that we have graphed them using percentages. The percentages that appear represent the number of times that topic occurred within the posts at that camp.
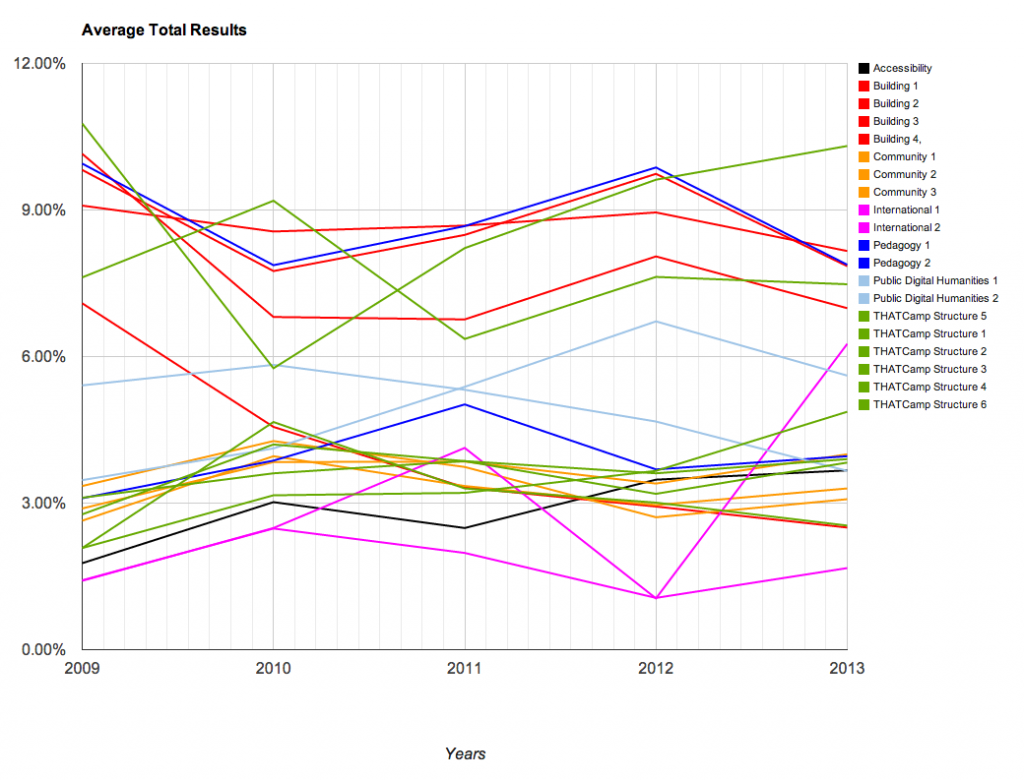
- Topics Overall
|
|
|
|
|
|
|
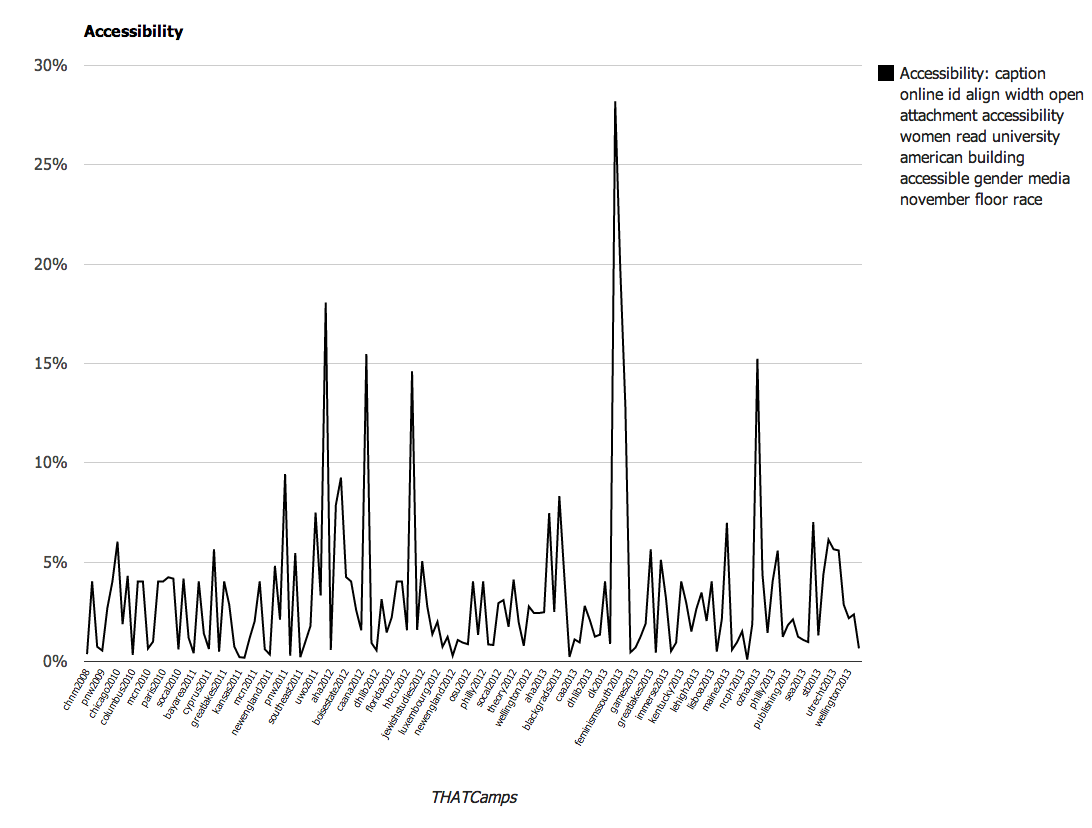

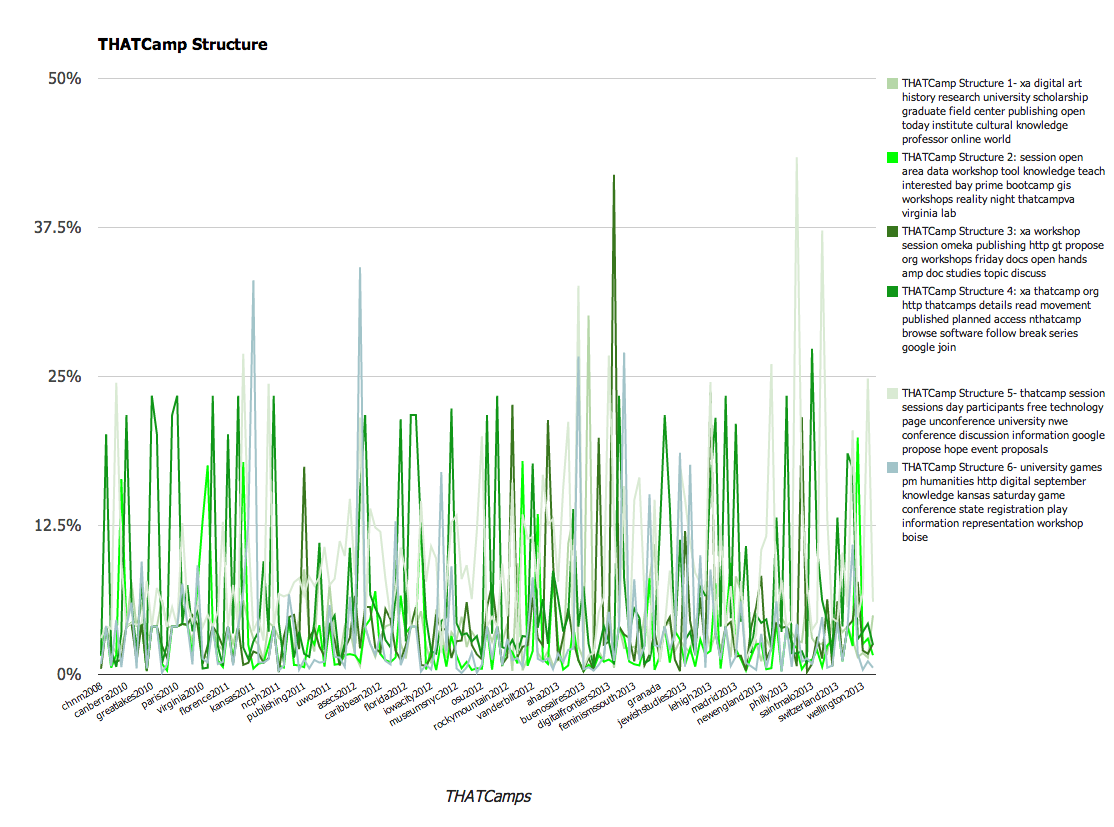

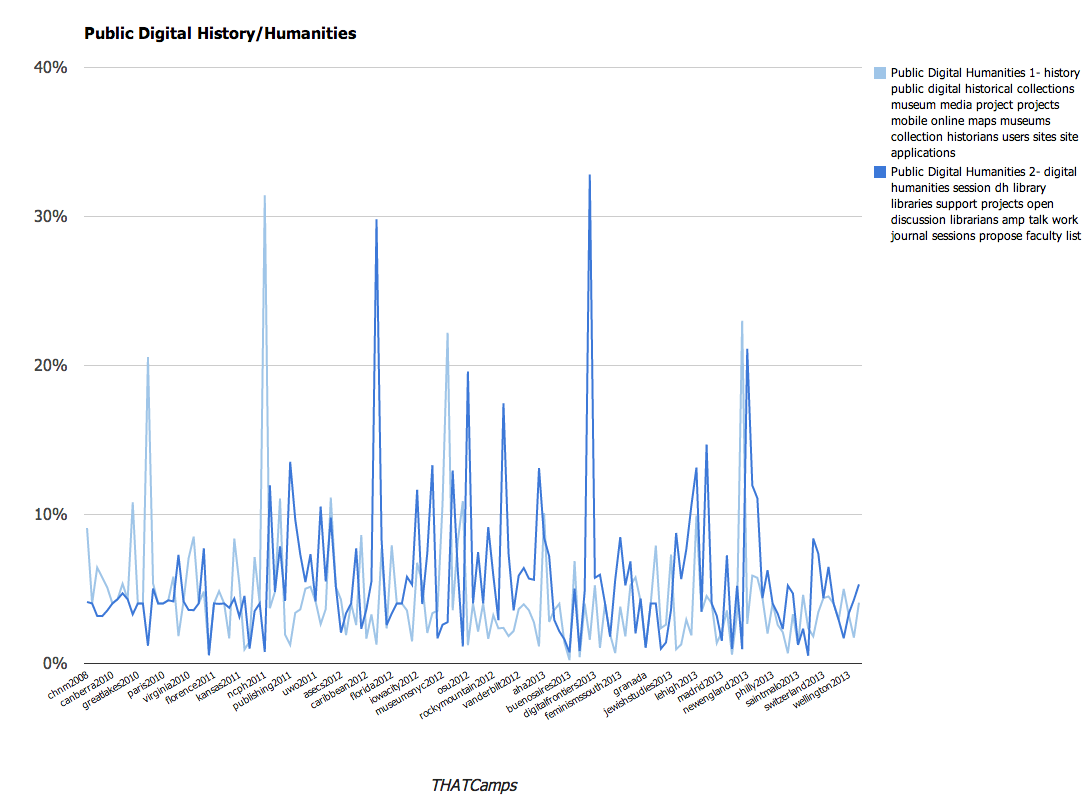
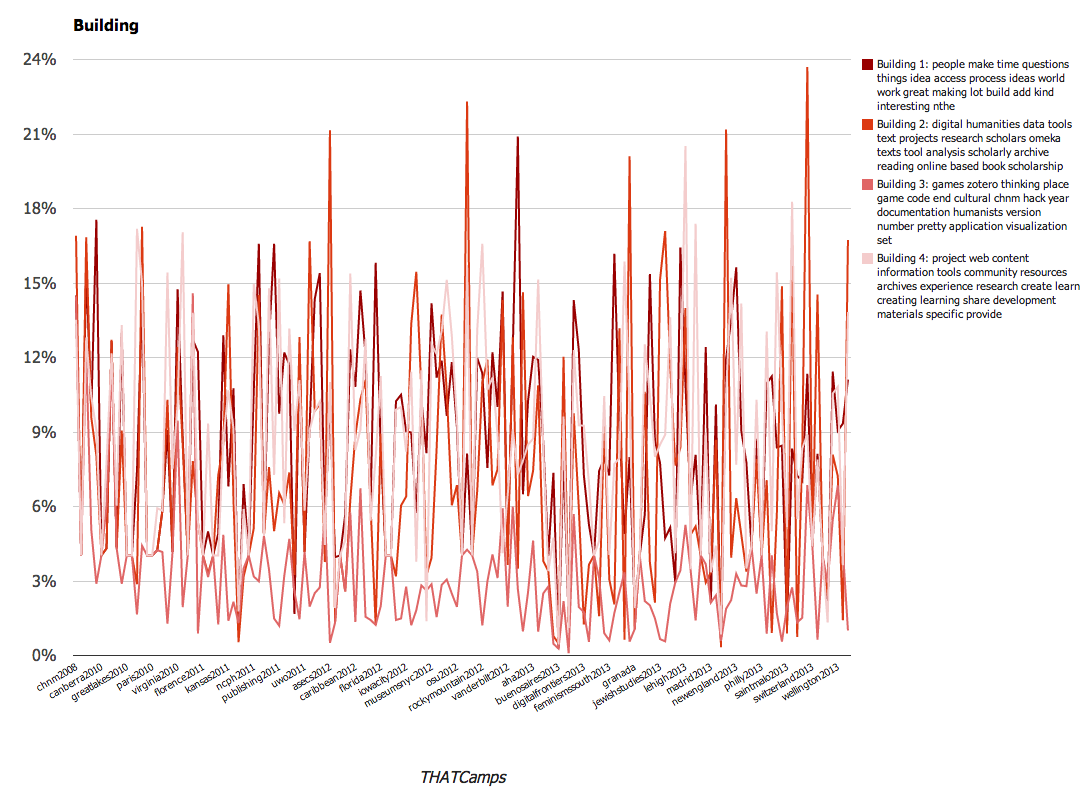
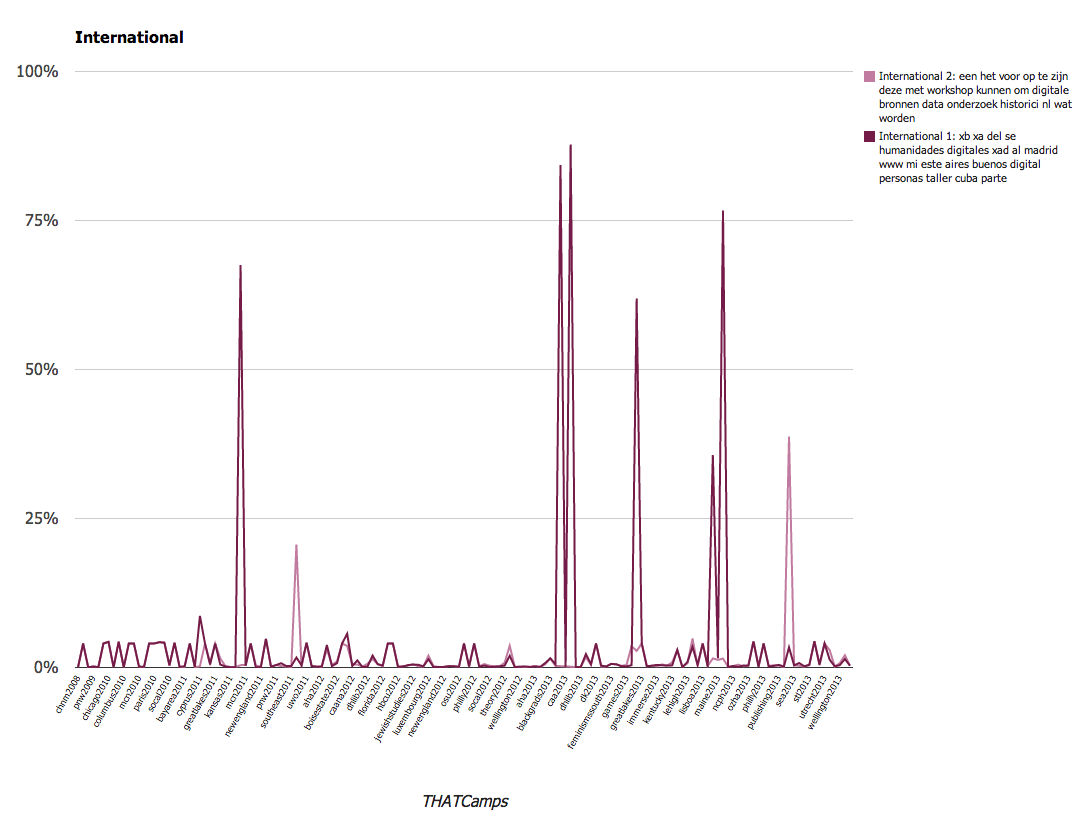
We found these results to be particularly interesting. A larger overall conclusion is that THATCamp content emphasizes the various applications of digital technology to scholarship, from public uses to tool building or teaching. Since THATCamp was founded, it has become a more varied community. However close examination of the topic models this exercise produced reveals that a number of the same terms appear frequently across all of the topic models (“digital”, for instance, appears in 8 of the 20 topics). This references the way in which ideas are circulated throughout camps and unifies the community. It also reflects the subjects that are the focus of the community.
If you’re interested in the data, you can view the various files here:
- Averages for each year and the overall chart (Google Spreadsheet)
- Data for each individual camp and charts by grouping (Google Spreadsheet)
- Data from MALLET
- Raw data
Unexpected Challenges Result in Important and Informative Discussions: a transparent discussion about stripping content and stopwords
(This post was created in the Spring of 2014 as part of a collective project undertaken by the 2013-2014 cohort of Digital History Fellows at RRCHNM. Each of the subsequent posts (written by individual fellows or collectively) originally appeared at the Digital History Fellowship Blog. These posts have been added to my blog to provide an comprehensive representation of the project. When these posts were written by others, I have noted the authorship.)
As described in previous posts, the first year Digital Fellows at CHNM have been working on a project under the Research division that involves collecting, cleaning, and analyzing data from a corpus of THATCamp content. Having overcome the hurdles of writing some python script and using MySQL to grab content from tables in the backend of a Wordpress install, we moved on to the relatively straightforward process of running our stripped text files through MALLET.
As we opened the MALLET output files, excited to see the topic models it produced, we were confronted with a problem we didn’t reasonably anticipate and this turned into a rather important discussion about data and meaning.
As a bit of background: topic modeling involves a process of filtering “stopwords” from a data set. Frequently a list of stopwords includes function words, or terms that appear repeatedly in discourse, like: “a, an, the”. These are filtered out because they serve a grammatical purpose but have little lexical meaning. Additionally, errors, misspellings, and lines of code that were skipped in the previous steps can also be filtered out at this stage.
As we opened the file of keys produced by MALLET, we found that some terms appeared that raised questions about what should or should not be included in our analysis. In particular, the discussion centered around spelling errors and function words in Spanish and French.
The conversation that followed, reproduced below, was significant and as people look through the results of this project or consider their own efforts reproduce something like this elsewhere, we’d like to be transparent about the decisions we made and, perhaps, spur a discussion about how to address scenarios like this in the future.
_____________________________________________
Take a look at what MALLET spit out: there are some errors.
Stuff like “xe, xc, zijn, xb, en, la”.
Yeah, I saw that.
We can make a custom stoplist to remove those.
Make a list and we’ll add it.
Interesting keys though - did you see that "women" came up in #0?
I’m excited to see this once it’s all graphed.
There’s some stuff though that I’m not sure we want to remove: Is CAA an error or an abbreviation? “socal” - is that social misspelled or Southern California, abbreviated?
Hmm, that could be an organization..
Yeah, SoCal, as in Southern California.
There was a camp there.
This adds a larger question: do we remove misspellings?
For clarity?
I have mixed feelings.
Me too.
I think it’s appropriate to remove backend stuff-
tags and metadata, but content is not something we should modify.
I agree.
We don’t want to skew the results.
Some of it occurred when we stripped all the alphanumeric stuff out.
It took out apostrophes- causing words like “I’ve” to become “I ve”.
The errors in themselves are telling about the nature of THATCamps.
That the content is generated spontaneously
lends itself to deviations from appropriate spelling ect.
I agree
Look at #17 and 18.
Whoa, where did “humanidades” come from?
Oh, right! There are international conference posts in here too!
How do we handle this?
Its possible to strip out the camps that are not in English
or even to run analysis on them separately.
I don’t want to skew the results but this also throws things off.
I know.
I say we leave it. It shows a growing international influence.
We’ll be able to see the emergence of International THATCamps.
I’ve never run into this before.
It brings up some interesting issues -
I wonder if there is standard procedure for something like this.
What about things like “en” which is Spanish for “is”-
that would have been removed on an English stoplist.
And now function words in Spanish and French
seem to appear more frequently because
the English terms have been filtered out.
How do you do topic modeling with multiple languages?
What about special characters?
We’ve stripped stuff out, how about how that would affect the appearance of words?
We have to find a stoplist for each of the languages.
To strip out the function words of all of them.
Good call. This got complicated quick!
Agreed.
_____________________________________________
As outlined above, when we opened the text file with keys, new questions were raised about the relevance and complications of running a particular stoplist on a corpus of texts. Similarly, we were forced to rethink how we handle misspellings and unfamiliar abbreviations. In the end, we tracked down stoplists for Spanish (and French) terms, so that no function words in any language would skew the results of our analysis. We also carefully examined the keys to identify abbreviations and misspellings and decided that they are a significant contribution to the analysis.
A few questions remained for us: how might removing non-alphanumeric characters (a-z,A-Z,0-9) alter the meaning of special characters used in languages other than English? How have others responded to spelling errors? How significant are errors?
Hopefully a post of this nature will foster discussion and produce a stronger, more complete analysis on this and other documents.
Pre-processing Text for MALLET
(This post was created in the Spring of 2014 as part of a collective project undertaken by the 2013-2014 cohort of Digital History Fellows at RRCHNM. Each of the subsequent posts (written by individual fellows or collectively) originally appeared at the Digital History Fellowship Blog. These posts have been added to my blog to provide an comprehensive representation of the project. Pre-processing Text for MALLET was written by Amanda Regan.)
In our previous post, we described the process of writing a python script that pulled from the THATCamp MySQL Database. In this post, we will continue with this project and work to clean up the data we've collected and prepare it for some analysis. This process is known as "pre-processing". After running our script in the THATCamp database all of the posts were collected and saved as text files. At this stage, the files are filled with extraneous information relating to the structure of the posts. Most of these are tags and metadata that would disrupt any attempts to look across the dataset. Our task here was to clean them up so they could be fed into MALLET. In order to do this, we needed to strip the html tags, remove punctuation, and remove common stopwords. To do this, we used chunks of code from the Programming Historian's lesson on text analysis with python and modified the code to work with the files we had already downloaded.
Defining a Strip Tags Function
We began by writing some functions so that we could import and call all of them at once. First, we removed the html tags from the document. Essentially we asked python to look at each character in the document and locate each opening tag, '<'. If an opening tag was identified, it would ignore it and any following characters until the closing tag, '>'. We drew on the code that is used in the Programming Historian and modified it so that it would begin at the start of the text file. The end-result of the function was this:
def stripTags(pageContents): content = pageContents[0:] inside = 0 text = ' ' for char in content: if char == '<': inside = 1 elif (inside == 1 and char == '>'): inside = 0 elif inside == 1: continue else: text += char return text
The function begins at the beginning of a variable called page contents and essentially returns any character that is not in between the opening and closing html tags.
Removing Non-Alpha Numeric Characters
Next, we needed to define a function that would remove all of the non-alpha numeric characters in the text. Punctuation is removed because it also distorts the results of text analysis. Borrowing again from the Programming Historian we defined a function that imported regular expression functions. According to the python documentation a Regular Expression (RE) specifies a set of strings that matches it. The function we adapted from the Programming Historian asks python to remove everything that doesn't match the string of unicode characters defined by RE (A-Z,a-z,0-9). It then splits them into a list.
def stripNonAlphaNum(text): import re return re.compile(r'\W+', re.UNICODE).split(text)
Removing Stopwords
The last function we needed to define was one that would remove stopwords from the text. This process is meant to filter out common function words. We used the same function defined in the Programming Historian lesson and the open source list of stopwords that the lesson drew on to accomplish this.
The stop words were defined at the top of list of functions:
stopwords = ['a', 'about', 'above', 'across', 'after', 'afterwards'] stopwords += ['again', 'against', 'all', 'almost', 'alone', 'along'] stopwords += ['already', 'also', 'although', 'always', 'am', 'among'] stopwords += ['amongst', 'amoungst', 'amount', 'an', 'and', 'another'] stopwords += ['any', 'anyhow', 'anyone', 'anything', 'anyway', 'anywhere'] stopwords += ['are', 'around', 'as', 'at', 'back', 'be', 'became'] stopwords += ['because', 'become', 'becomes', 'becoming', 'been'] stopwords += ['before', 'beforehand', 'behind', 'being', 'below'] stopwords += ['beside', 'besides', 'between', 'beyond', 'bill', 'both'] stopwords += ['bottom', 'but', 'by', 'call', 'can', 'cannot', 'cant'] stopwords += ['co', 'computer', 'con', 'could', 'couldnt', 'cry', 'de'] stopwords += ['describe', 'detail', 'did', 'do', 'done', 'down', 'due'] stopwords += ['during', 'each', 'eg', 'eight', 'either', 'eleven', 'else'] stopwords += ['elsewhere', 'empty', 'enough', 'etc', 'even', 'ever'] stopwords += ['every', 'everyone', 'everything', 'everywhere', 'except'] stopwords += ['few', 'fifteen', 'fifty', 'fill', 'find', 'fire', 'first'] stopwords += ['five', 'for', 'former', 'formerly', 'forty', 'found'] stopwords += ['four', 'from', 'front', 'full', 'further', 'get', 'give'] stopwords += ['go', 'had', 'has', 'hasnt', 'have', 'he', 'hence', 'her'] stopwords += ['here', 'hereafter', 'hereby', 'herein', 'hereupon', 'hers'] stopwords += ['herself', 'him', 'himself', 'his', 'how', 'however'] stopwords += ['hundred', 'i', 'ie', 'if', 'in', 'inc', 'indeed'] stopwords += ['interest', 'into', 'is', 'it', 'its', 'itself', 'keep'] stopwords += ['last', 'latter', 'latterly', 'least', 'less', 'ltd', 'made'] stopwords += ['many', 'may', 'me', 'meanwhile', 'might', 'mill', 'mine'] stopwords += ['more', 'moreover', 'most', 'mostly', 'move', 'much'] stopwords += ['must', 'my', 'myself', 'name', 'namely', 'neither', 'never'] stopwords += ['nevertheless', 'next', 'nine', 'no', 'nobody', 'none'] stopwords += ['noone', 'nor', 'not', 'nothing', 'now', 'nowhere', 'of'] stopwords += ['off', 'often', 'on','once', 'one', 'only', 'onto', 'or'] stopwords += ['other', 'others', 'otherwise', 'our', 'ours', 'ourselves'] stopwords += ['out', 'over', 'own', 'part', 'per', 'perhaps', 'please'] stopwords += ['put', 'rather', 're', 's', 'same', 'see', 'seem', 'seemed'] stopwords += ['seeming', 'seems', 'serious', 'several', 'she', 'should'] stopwords += ['show', 'side', 'since', 'sincere', 'six', 'sixty', 'so'] stopwords += ['some', 'somehow', 'someone', 'something', 'sometime'] stopwords += ['sometimes', 'somewhere', 'still', 'such', 'system', 'take'] stopwords += ['ten', 'than', 'that', 'the', 'their', 'them', 'themselves'] stopwords += ['then', 'thence', 'there', 'thereafter', 'thereby'] stopwords += ['therefore', 'therein', 'thereupon', 'these', 'they'] stopwords += ['thick', 'thin', 'third', 'this', 'those', 'though', 'three'] stopwords += ['three', 'through', 'throughout', 'thru', 'thus', 'to'] stopwords += ['together', 'too', 'top', 'toward', 'towards', 'twelve'] stopwords += ['twenty', 'two', 'un', 'under', 'until', 'up', 'upon'] stopwords += ['us', 'very', 'via', 'was', 'we', 'well', 'were', 'what'] stopwords += ['whatever', 'when', 'whence', 'whenever', 'where'] stopwords += ['whereafter', 'whereas', 'whereby', 'wherein', 'whereupon'] stopwords += ['wherever', 'whether', 'which', 'while', 'whither', 'who'] stopwords += ['whoever', 'whole', 'whom', 'whose', 'why', 'will', 'with'] stopwords += ['within', 'without', 'would', 'yet', 'you', 'your'] stopwords += ['yours', 'yourself', 'yourselves']
The function definition was called below all of the other functions:
def removeStopwords(wordlist, stopwords):
return [w for w in wordlist if w not in stopwords]
The function essentially asks python to compare a list of words called 'wordlist' to the list of stopwords defined above. It returns every word not defined in the list of stopwords.
We named the file with all of these functions 'rmv.py' and then started a new python script that would import these functions and apply them to all of the text files we downloaded from the THATCamp database.
Defining a script to remove all of the tags
After we had defined all the necessary functions to remove html tags, strip out any non-alphanumeric characters, and remove stopwords, we needed to write a script that would import and apply all of these functions.
First, we import both the os and sys modules so that we can ask python to interact with the files located on our computer. We also import the rmv file that contains all of the functions.
import os, sys import rmv
Next, we begin to define a loop that will apply each of those functions to a text document and then loop back and continue until it has done this with every text file. Setting x = 1 allows us to define where in the list of documents the script to start and we also instruct python to only complete the following loop while x is less than 300. This gives python a starting and stopping point.
x = 2 while x < 300:
Everything that follows the 'while' statement is part of the loop and we'll use a try and except statement to tell python what to do if a file doesn't exist. We begin by defining the file name and opening the text file. In the previous post, we downloaded all of the posts from each that camp and named them 'wp_x_posts.txt'. 'X' increased sequentially and matched the table number in the THATCamp database. We'll do the same thing here asking python to open a text file called 'wp_x_posts.txt' and increase x sequentially each time it loops through. We use the os commands to open the file, read it, and then store it in a variable called content.
try:
f = open('wp_' + str(x) + '_posts.txt', 'r')
content = f.read()
Now that python has opened and read the content we can begin to call the functions we defined in 'rmv.py' on the content. We'll work through those functions in the order we added them to the 'rmv' module and call them using several variables. First, we call 'rmv.stripTags' on the content variable we defined above and store it in a variable called 'words'. Then we call 'rmv.stripNonAlphaNum' on the variable words we just created and store it in a variable called 'fullwordlist'. We've now removed the tags and all of the non-alphanumeric characters from the post. The final function we need to call is the 'removeStopwords'. We have to define what to remove the stopwords from and where the stopwords can be found. To do this we call the function we defined, 'rmv.removeStopwords', on 'fullwordlist' and ask it to remove any of the words from the stoplist by referring to 'rmv.stopwords'. We tell python to store this all in a variable called 'wordlist'.
words = rmv.stripTags(content).lower() fullwordlist = rmv.stripNonAlphaNum(words) wordlist = rmv.removeStopwords(fullwordlist, rmv.stopwords)
Now that python has stripped the tags, non-alphanumeric characters, and the stopwords from the file the resulting text is in a variable called wordlist. That data needs to be re-written to the file. To accomplish this we asked the os module to create a new file, defined as 'fo' rather than 'f' this time, and open the same string as before: 'wp_x_posts.txt'. Then we tell it to write fo to the file with a line break after each word. However, because the text in wordlist is now a python list we have to instruct python to write a list rather than a string to the file. To do this we call '.join' on the wordlist variable which is a built-in type in python that concatenates the lists. The '.join' function combines a word list into a string and by adding a line break, '/n', each of our words is returned neatly onto a new line in our file.
fo = open('wp_' + str(x) + '_posts.txt', 'w')
fo.write('\n' .join(wordlist))
Lastly we need to tell python what to do if a file doesn't exist and add one to the loop causing it to repeat on the next sequentially numbered file. The except statement here tells python what to do if a file doesn't exist. Normally it would throw an error and stop the script from running but by telling python to clear the exception it just ignores the error. Finally, adding one to x causes the script to repeat.
except Exception: sys.exc_clear() x += 1
The result is 191 cleaned up text files ready to be processed using MALLET.
Extracting Data from the THATCamp Database Using Python and MySQL
(This post was created in the Spring of 2014 as part of a collective project undertaken by the 2013-2014 cohort of Digital History Fellows at RRCHNM. Each of the subsequent posts (written by individual fellows or collectively) originally appeared at the Digital History Fellowship Blog. These posts have been added to my blog to provide an comprehensive representation of the project. Extracting Data from the THATCamp Database was written by Amanda Regan.)
This week we've continued to work on building a python script that will extract all of the blog posts from the various THATCamp websites. As Jannelle described last week, our goal was to write a script that downloads the blog posts in plain text form and strips all of the html tags, stopwords, and punctuation so that we can feed it into MALLET for topic modeling and text analysis. After several long days and a lot of help from second year fellow Spencer Roberts, we've successfully gotten the code to work.
To recap, the script should do the following:
- connect to the mySQL database
- select the relevant table using a sql query.
- open a text file and write the content from the database
- loop over the code and do this for each table
Connecting to the MySQL database has to be done in two places. First in the terminal using a secure shell and secondly in the script. To connect in the terminal, we used a secure shell port tunnel which allowed our computer to communicate with the database.
ssh -L 3306:localhost:3306 user@host.edu
Next, we began writing a python script that would connect to the database and download all of the blog posts from each of the THATCamp sub-sites. The THATCamp website is a wordpress multisite install with multiple tables for each individual THATCamp (over 200 individual camps). The blog posts are stored in a table labeled 'wp_xx_posts', with xx being the number assigned to a particular THATCamp. To complicate matters, the posts are not perfectly sequential. There are several skipped numbers for content that has been deleted or created erroneously. Our script would need to respond to these challenges.
The first step was to import the relevant python libraries. For this script, we first imported the MySQLdb module and asked python to refer to library as 'mdb'. We also imported the os python module which allows the script to interact with the operating system. In this case, we used it to open and write to text files.
import MySQLdb as mdb import os
The next portion of the script defined a loop and designated where in the database to find the blog post data. Because of the naming convention we needed python to start by looking for wp_1_posts and continue to run the same operation for each sequentially numbered table.
x = 1 while x < 500: table= 'wp_' + str(x) + '_posts' query= "SELECT post_content FROM "+ str(table) + " WHERE post_status = 'publish' AND post_type = 'post'"
The beginning portion of the code defines a loop and tells python to begin at 1 and count up to 500. Each time python loops back it will look for a table named ‘wp_x_posts’. The script then defines a MySQL SELECT query which tells python where to look for the content and defines what content it should pull. In this case, we had to specify that the query should pull the contents of data that matched the following criteria:
- In the post_content column
- From the table defined by the string above (wp_x_posts where x increases sequentially each loop)
- Where the Post_status is published
- And where the Post_type is post
So far the code has given python instructions on where to query the information from and has set up a loop. The next step is to actually tell python how and where to connect to the database as well as what to do with the information it receives. First, python should open a new file and save it with the same name as the table. The string defined above will name the file wp_x_posts.txt and will count up sequentially because of the loop. The file permission is set to ‘a’ so that python can add to the document each time it pulls a row from the database.
f = open('wp_' + str(x) + '_posts.txt', 'a')
Next, we set up a compound statement in python using try and except to create a statement that will download and write the content to the file. It will also provide an exception that will tell python what to do if the table doesn’t exist in the database.
try: con = mdb.connect(host="127.0.0.1", port=3306, user="usrname", passwd="pass", db="clone-thatcamp"); cur = con.cursor() cur.execute(str(query)) rows = cur.fetchall() for row in rows: line = str(row) f.write(line +'\n')
The MySQLdb module that we imported at the top of the script uses the cursor method to create a cursor object for processing MySQL statements. The cursor is first created then it executes the query which we defined above. It then fetches all of the rows that are returned by the query and prints each one to the open text file. It prints the rows one by one inserting a line break after each one.
An additional challenge, described above, was that while tables in the database were numbered sequentially, there are occasional skips. For example there isn’t a "wp_1_posts" but there is a "wp_2_posts". When we were writing the script we kept encountering an error when python couldn’t find a table. To get around this we used the except statement. The except statement tells python to remove the empty text file if the table does not exist so that we don’t have a bunch of empty and useless text files. Using the operating system function, python deletes any file that it can’t pull data for.
except:
os.remove('wp_' + str(x) + '_posts.txt')
f.close
Finally, python adds one to x, causing the script to loop back to the top and follow the instructions for each sequential table.
x += 1
When we ran the program it downloaded over 200 plain text files for us to work with. However, the files were often a mess. They had html tags and some very odd formatting so we had to go through and clean them up. Our next blog post will describe how we cleaned up these text files to prepare them for topic modeling with MALLET.
The final code looks like this:
import MySQLdb as mdb
import os
x = 1
while x < 500:
table= 'wp_' + str(x) + '_posts'
query= "SELECT post_content FROM "+ str(table) + " WHERE post_status = 'publish' AND post_type = 'post'"
# save as file
f = open('wp_' + str(x) + '_posts.txt', 'a')
try:
con = mdb.connect(host="127.0.0.1", port=3306, user="usr", passwd="password", db="clone-thatcamp");
cur = con.cursor()
cur.execute(str(query))
rows = cur.fetchall()
for row in rows:
line = str(row)
f.write(line +'\n')
except:
os.remove('wp_' + str(x) + '_posts.txt')
f.close
x += 1
Download the entire code here.
Spring Semester in Research and a THATCamp Challenge
(This post was created in the Spring of 2014 as part of a collective project undertaken by the 2013-2014 cohort of Digital History Fellows at RRCHNM. Each of the subsequent posts (written by individual fellows or collectively) originally appeared at the Digital History Fellowship Blog. These posts have been added to my blog to provide an comprehensive representation of the project. When these posts were written by others, I have noted the authorship.)
The spring semester is here and the first year DH fellows have begun our rotation into the Research division of CHNM.
To get the ball rolling, we spent a week working through the helpful tutorials at the Programming Historian. As someone new to DH, with admittedly limited technical skill and knowledge, these were immeasurably useful. Each tutorial breaks content into smaller, less intimidating units. These can be completed in succession or selected for a particular topic or skill. While there is useful content for anyone, we focused our attention on Python and Topic Modeling with the aim of solving our own programming dilemma.
Our central challenge was to extract content across the THATCamp Wordpress site to enable us to do some text analysis.
THATCamp, or "The Humanities and Technology Camp", an unconference begun in 2008 at George Mason University, provides participants with space to collaborate and discuss the intersection of technology and the humanities. In five years there have been 148 THATCamps (Amanda French, THATCamp coordinator, works out the scale and scope of the camp’s impact in a blog post here).
Each THATCamp has their own domain containing various posts about the event, proposals from attendees, and notes from sessions (for example: dc2014.thatcamp.org). While some camps are more active than others, every camp generates a large number of distinct posts. All of that content is uploaded to one multi-site Wordpress install. On the backend, every additional THATCamp is given a distinctive number and a brand new set of tables is created (with upwards of 10 tables for each camp). With 148 separate camps (and an additional 32 upcoming camps), that translates into a massive database.
Given the wealth of information available, the THATCamp website offers an attractive opportunity to examine trends in DH discussion. However, there is no effective way for individuals to do so. If one wanted to learn more about the content discussed across multiple THATcamps, he or she could, theoretically, go to each individual page to read the text, but given the sizable amount of posts and the available, a more efficient option is necessary.
The goal of this project is to create a program using MySQL and Python that will allow us to collect the content available on the site and prepare it for further analysis (using tools like MALLET). This will require several steps:
- access wordpress content which is stored in a MySQL database
- create python code that logs into the database remotely
- identify the tables from each THATCamp’s wordpress site within the database.
- they are labeled sequentially i.e “wp_2_posts”, “wp_3_posts”, ect and interspersed with other tables like “wp_5_terms” and “wp_42_comments”.
- grab content from each table that contains the blog posts
- identify the difference between posts, pages, attachments (information found in the “post_type” column) and “publish” or “inherit”
- query the content so that the script only pulls posts (not pages or attachments) and only published posts (rather than drafts).
- create a text file of that content and save it
- loop through the previous steps with each successive table until done.
Essentially, python builds the string using MySQL, drops it into the Wordpress content as a query, where it digs around for the correct data until it receives the content back and then saves the file.
After all that content is downloaded, it needs to be cleaned up. Each post may (or may not) contain some stylistic information and deleted/modified posts may produce error messages that require a bit more work. There are two ways to do this: write another program to open each of those text files and strip out tags, then save them again as text files. Or, we can get the first string to work, then add additional scripts that process out the tags before saving the text file. Then the content is ready for analysis using tools like MALLET.
Public Projects: Reflection
The past seven weeks have moved really quickly but I have benefitted a great deal from the time we spent in the Public Projects section of CHNM.
Due to my relatively limited technical skills, this section has proven to be the most challenging thus far. However, with some help, and some pretty detailed instructions, I have been expanding my skill set and feel a lot less intimidated by the tools we work with. There are three main projects on which we focused: testing updates in Omeka, transcribing and revisiting documents at the Papers of the War Department and contributing to and testing the National Mall site.
I have deeply enjoyed them all, especially the sunny morning we spent at the National Mall. Additionally, a great deal of our work overlapped with the theoretical reading and discussions of our coursework as digital history scholars. It is rare for theory and application to be balanced, but that was definitely my experience this semester. I was frequently surprised to find applications of class reading at work and often referred to the work done at CHNM during course discussions.
Public Projects was deeply inclusive for us as fellows. I got a real sense of each of the ongoing projects and I learned a great deal about the collaborative work required to produce the resources described above.
Overall, this semester the fellowship has given me a structured place to develop my knowledge and expertise with digital tools, like Omeka and Scripto, and given me a sandbox to play with Git Hub and the command-line (if you know what those things are, you are in a much better place than I was three months ago!)
I’m looking forward to learning more in the semester to come!
Education Dept. Reflection
My time in the education department at CHNM has passed quickly, but it has also been deeply enriching. I’ve learned a lot about the challenges of creating historical scholarship geared toward K-12 students and have come to appreciate the importance of integrating digital media in the classroom. As one can imagine, coming into the Center with limited technical skills can be intimidating, but in these seven weeks the combination of course content and fellowship activities has greatly reduced my concerns.
Upon reflection, I have to say that education was a great area of the center to start this DH journey. The projects in this area are geared toward the development of historical thinking skills for teachers and students, but realistically the sites created and maintained at CHNM serve anyone with an interest in history. In fact, they have been crafted intentionally to attract and serve a wide population. Not only has this been motivational to me, it has convinced me of the value of digital history and helped me to see that the act of engaging students can (and should) be performed in a myriad of ways.
Given my background and research interests, I’ve been thinking, particularly, about issues of access and underserved populations as we move our work online. In evaluating websites that provide historical content, like Prohibition and Cape Cosmos I’ve begun to seriously contemplate the ways in which historical interpretations can be presented digitally. Further, the process of testing (and in some cases, breaking) some of the sites that are in-development now at the Center helped me to consider layout, design and functionality from a new perspective. As a former instructor, the discussions we’ve had about using digital tools for student engagement were especially meaningful for me and as a result I have begun to share tools and websites with nearly every educator I know.
Overall, though, I must say that working in a team has been the most meaningful aspect of the experience thus far. Not only has the education department been forthcoming with delicious treats each week, members are consistently welcoming and eager to discuss projects and ideas with us. Given my lack of expertise on these areas, working on a small part of the large-scale projects produced at the CHNM has given me greater insight into their creation and maintenance.
Introductions
My first introduction to the Center for History and New Media happened without my even realizing it. As a graduate student at Gallaudet University, a professor urgently encouraged us to begin using Zotero and as I rounded the corner on two Masters theses, the value of this tool was not lost on me. Only after I had begun the process of applying to history programs did I realize that my favorite citation tool had its origins here at George Mason University and CHNM.
As I have come to learn, CHNM exists on the edges of what-historians-are-doing and what-historians-will-be-doing. Each of the three divisions, Education, Public Projects and Research, has an exploratory and collaborative thrust. Projects developing here seek to expand the intersection of technology and historical scholarship and, simultaneously, make those resources and tools available to students, teachers, and scholars.
The Education division, also known as Teaching and Learning, makes a number of primary sources and teaching materials available to teachers and administrators through projects like Children and Youth in History and Exploring US History. Projects like this connect vast archival and primary resources that may otherwise be inaccessible to teachers and students in disparate parts of the country. The next division, Research and Tools, extends those efforts to scholars, librarians and museum professionals by providing training on new digital tools for the collection, storage and presentation of historical collections and projects. History Departments Around the World, for instance, links history departments enabling scholars and educational programs to collaborate, locate research items or collaborate with colleagues. Zotero, which I can’t more highly recommend (download it now, really) is also housed in the Research and Tools section of CHNM. The free and easy-to-use tool will change the way your manage sources and the addition of a tagging feature will convert your reference list into a tool for making even more connections between sources. Finally, the Public Projects section, also known as Collecting and Exhibiting, takes on the presentation of history through digital records and historical exhibits. An exciting new project, due to be released this March, is the Histories of the National Mall. This exhibition will provide a digital and mobile interface that can be used in the exploration of the National Mall. Another project, The Papers of the War Department 1784-1800 has made 55,000 documents available to researchers and students through their website.
I am new to the field of Digital History but eager to learn more about the potential of digital projects to engage public in new and meaningful ways. I have a passion for making history accessible to scholars and community historians and the emphasis in CHNM on this effort will better prepare me for my long-term goals of preservation and presentation of historical materials both inside and outside of the classroom.